Real World Data: Sources and Effective Evaluation

This Article Will:
- Help you understand what real world data (RWD) is and how it is used.
- Discuss the many sources of RWD and how tracking and measuring RWD can be challenging. This article will help you understand these different sources and how to evaluate them.
- Provide a list of questions at the end that you can share with your internal teams to standardize how you evaluate RWD and get the most out of your data providers.
Key Takeaways from the Article:
- As the name implies, real world data are generated during routine clinical practice and not in a clinical trial. Analysis of RWD leads to real world evidence, an important element in precision medicine.
- RWD can be gathered from different sources such as electronic health records, registries, claims data and social media. Different sources provide different insights but also have different challenges associated with them.
- Data providers collect, clean and manage RWD from the different sources and provide easy access. options. A series of questions can help companies evaluate different data providers and select the one that offers the most relevant data and customer support.
The last two decades have brought unprecedented changes to healthcare that profoundly impact the entire healthcare ecosystem including how drugs are developed, approved and marketed. Real world data and evidence play an increasingly important role, especially in the context of precision medicine.
What are Real World Data?
Randomized controlled clinical trials (RCT) have been the gold standard for demonstrating the efficacy and safety of drugs. In RCTs drugs are administered to carefully selected patients who are closely monitored for both drug efficacy and adverse events. Once approved the drug then reaches a much more diverse patient population, e.g. patients of different races or ethnicities, a wider age range and with different co-morbidities. This broader use generates new data “real world data” (RWD) and insights “real world evidence” (RWE) about drug efficacy and adverse events that were not apparent in the selected RCT group.
The FDA defines RWD and RWE as follows: “Real world data are the data relating to patient health status and/or the delivery of health care routinely collected from a variety of sources.”
Real world evidence is the clinical evidence regarding the usage and potential benefits or risks of a medical product derived from analysis of RWD.
Stakeholders including drug manufacturers, academic and governmental researchers as well as regulatory bodies worldwide are increasingly using RWD/RWE, especially in the context of precision medicine. Granular patient-level RWD play an increasingly central role in the context of selecting the best treatment option for patients.
Sources of RWD
Real world data can be obtained from many different sources. Tracking these sources and understanding which are best for your company can be challenging. The most common options are:
- Electronic health records (EHRs)
- Disease or patient registries
- Medical claims and billing data
- Patient-generated data from patients, providers, wearables or apps
- Supplemental information collected alongside RCTs
- Pragmatic clinical trials
- Social media
- Patients’ health status and outcomes data from: Image data, Lab, Molecular profiling (genetic testing), Digital biomarkers, Family history, Long-term care
Gathering these various components for your company can be difficult to organize but highly beneficial once compiled.
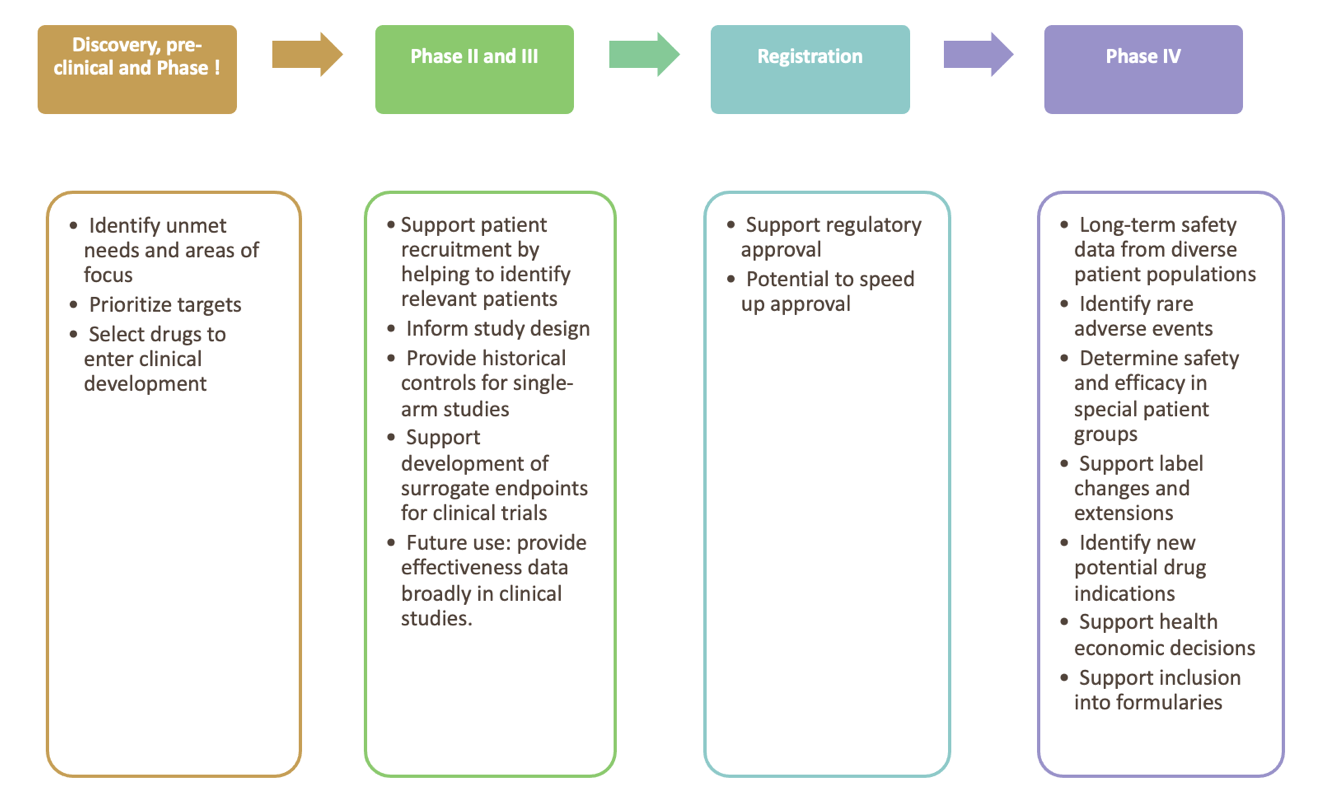
Current and future uses of RWD
Figure 1 summaries the use of real-world data and evidence for product life cycle management
The Impact of COVID on RWD
The COVID pandemic is having a profound impact on all aspects of RWD quality, generation, collection and use, specifically:
- HCPs saw fewer patients as treatments were delayed and the use of telehealth increased. Together this resulted in a significant reduction of medical claims during 2020 and into 2021 as well as changes to prescribing patterns impacting data related to healthcare cost and patient outcomes.
- Some patients avoided their HCP’s office due to losing access to health insurance, fear of the virus in an office, or not wanting to wear a mask or get vaccinated to be seen.
- Clinical studies unrelated to COVID also decreased affecting the collection of supplemental RWD in connection with these studies.
- COVID and COVID treatments, including off-label treatments with drugs like hydroxychloroquine, have confounding effects on RWD collected from patients, especially those with pulmonary and autoimmune disorders.
- Patients suffering from “long COVID” are as of now an unknown potentially cofounding factor affecting RWD as they might react differently to treatments than patients with the same disease who did not contact COVID or don’t suffer long-term effects.
- Vaccination history and testing records will complicate data by increasing volume.
In the future, the effects of the COVID pandemic on type, volume, quality and nature of RWD need to be considered when RWD are analyzed and used to generate RWE and medical insights.
Validity of RWD and RWE
Data reliability and relevance
The old adage “garbage in, garbage out” also holds true for RWD. Data reliability and relevance are two main factors that are of critical importance when collecting RWD.
- Data reliability, incl. data accrual and quality control. Reliability means that the data adequately represent the underlying medical concepts they are intended to represent. Data provenance is critical to establish reliability. Examples of reliable data are:
-
- Medical claims data that are properly coded using the International Classification of Diseases (ICD) codes.
- Laboratory results that are checked for completeness, consistency and trends over time.
- Relevance of data assesses whether the data are fit for purpose, that is are they appropriate to answer the medical question.
-
RWD are from many different sources and therefore challenging to use for drug developers and to evaluate by regulatory bodies. Challenges associated with RWD use are:
- EHR data are generally not standardized and cannot readily be extracted, used and compared between different systems. Unstructured data, such as doctors’ notes and social media data, are even more difficult to access.
- While medical claims data are highly useful and fairly readily available, they can lack granularity to answer the scientific question a study needs to answer.
- Patients in RCT are highly selected while RWD comes from diverse populations with covariates that confound results, e.g. obesity, smoking, alcohol use.
- Relevant changes to a patient’s health might be captured late or not at all in their EHR, e.g. worsening of existing conditions such as asthma, depression or increased pain.
- Integration of health records across different health care systems is often impossible due to interoperability of health care systems. As patients move between providers and/or insurers health data might be lost.
- Collecting expansive health information about individual patients, while useful in the context of RWD generation, raises privacy and consent challenges.
- Some data, e.g. a portion of claims data can suffer from low validity, e.g. due to fraud, like ordering unnecessary tests or billing for services that were not provided.
Extraction of meaningful data from unstructured sources remains a major issue, but advances in natural language processing (NLP) continue to make this process more feasible.
Generating RWE from RWD
Real world evidence is generated when RWD are analyzed with the appropriate analytic techniques to provide meaningful and actionable insights.
Data analysis can introduce additional problems that can impact the validity of a study. Common challenges associated with data analysis are:
- Biases that are introduced when a confounding factor, e.g. the age of the patients or severity of the disease, influence the outcome making it difficult or impossible to tease apart how much of the health outcome can be attributed to the treatment vs. the confounding factor.
- Biases can also be introduced during the training of machine learning models. Using a biased training library bakes that bias into the algorithm invalidating subsequent analyses. These biases are difficult to detect and can be time consuming and difficult to remedy. As analyses are increasingly performed by machine learning algorithms, standards and common data models need to be created.
- Analysis of big data can also create a “needle in the haystack” problem: the fine line between a weak signal and noise can lead to wrong interpretations, especially given the human tendency to look for patterns until a preconceived idea is supported by some evidence in the data.
- Data silos is another big issue, storing data sets in disparate data silos that are not connected with each other make it impossible to generate deep insights.
- Lack of standard data analysis pipelines make consistent analysis difficult.
- Analyzing big data requires a specific skill set that is hard to find. Data analysts that also understand drug development are even scarcer. The lack of trained employees therefore can be a limiting factor for broader use of RWE.
- Even given sufficient resources, modern day data analysis is too complex for individuals to take on alone but requires collaboration of interdisciplinary internal teams and with external partners. Sharing not just data, but analysis results and code remains a challenge.
- Differences in coding practices between regions create challenges for analysis by potentially requiring the user to be familiar with coding schemes, differences in data coverage, and coding changes by CMS (POC codes), AMA (CPT and HCPS codes), WHO (ICD codes), The Universal Lab Order Codes, etc, as well as data coverage differences in different regions.
Despite these drawbacks and challenges, the use of RWD and RWE across the entire drug and medical device lifecycle is bound to increase because they provide critical additional information that cannot be obtained any other way.
Accessing RWD
As discussed, RWD stems from disparate sources and collecting it in a way that makes it easily accessible and searchable is a big undertaking. Companies like H1 are specializing in collecting, cleaning and standardizing RWD and making them available with intuitive user interfaces and efficient search, sort and filter functions.
When evaluating data providers potential customers need to consider the following:
Data Type, Breadth and Scope
- Characteristics of the RWD a provider is offering?Type of data, e.g. claims data, social media data?
-
- What is the demographics of patients included in the database?
- Where was the data collected, e.g. which health system, clinical setting, geography?
- Breadth and depth of data, e.g. are all referral data captured or just some?
- Therapeutic areas covered, e.g. only specific or all including specialty markets?
- Sources of data, e.g. government agencies, associations, private sources?
-
- Are these validated, reputable sources/vendors?
-
- Do the data vendors have a validation process in place? If so how often is the process reviewed and what audits are performed?
-
- How often is the data updated, e.g., daily, weekly?
- How complete is the database? If it is older with new entries, where new fields added to newer records?
- How does the provider ensure reliability of the data?
-
- How does the provider ensure the data is unbiased?
- How does the provider clean the data to remove any duplication?
-
- Is that data provided sufficient to answer my scientific question, i.e. is it relevant?
- How is the data collected, cleaned and entered?
-
- Is verification/validation checking undertaken during and after data collection?
- What processes and QA procedures are used to integrate data from various vendors into the platform?
- Has the data been transformed in any way after collection?
- How are issues like duplication and double counting of records avoided?
- What procedures are in place for extracting data?
- To what end was the data collected? Might that motivation introduce a systematic bias?
- By whom and how is the data recorded? For example, through devices, collected in person or digital biomarkers? Does this process potentially introduce a bias?
- Can additional information be collected from the patients if needed
-
- How is the data analyzed?
-
- Mainly manual vs AI/machine learning (ML)-based approach?
- If ML is used, is there additional human QA to identify and resolve issues?
- Are ML models trained to avoid bias? What is the process?
-
- How does the vendor handle privacy restrictions?
-
- What is their process for GDPR standards? HIPAA?
-
- What are the options for Diversity & Inclusion (D&I) data?
-
- How familiar is the vendor with FDA guidance on D&I?
- Which data points are offered? What percentage of the data is related to D&I overall?
-
Platform Features
- How flexible are the search, sort and filter options?
- Are user interface and guidance intuitive?
- Is platform downtime minimal?
- Does the platform enable collaborative work, e.g. sharing of search results or lists, ability to annotate and share annotations?
- Does the company provide access to data only or do they perform data analysis?
-
- If so, how is the data analyzed? What methods are used? What quality assurance measures are in place?
- How can customers access the analysis, e.g., standard analysis packages/data reports, or customized fee-for-service reports?
-
- In addition to a platform to access data, does the vendor provide a data feed or API available for use within internal business tools?
Provider Company Features
- How knowledgeable about the industry is the customer success team? Can they advise customers on approaches to answer their specific questions?
- Does the company provide onboarding services that enable users to proficiently handle the tasks they need to?
- How responsive to customer requests is the data provider?
Equipped with these questions, you can now evaluate data providers and identify the one who has the most high-quality, complete RWD and the service offerings and support you need to use RWD to drive your business.

Yuwei Zhang, MD, MPH
Yuwei Zhang is a pathologist by training whose paper on esophageal cancer has been cited over 900 times. She has gained deep expertise in lifecycle management, data strategy, digital innovation, and competitive intelligence. She regularly gives talks at universities and has been invited to review manuscripts for top-tier medical journals, grant proposals, and books. She is the founder of Women Data Scientists in Baltimore that helps women become data scientists, and has twenty years’ experience in global healthcare including provider, payer, pharma, and advocacy groups.

Ariel Katz, CEO, Co-Founder
Ariel started his first company in college, ResearchConnection, to help connect students with research opportunities. That company grew to over 40 universities and was eventually acquired by the Jefferson Accelerator Fund, Bill and Melinda Gates Foundation and the Ewing Kauffman Foundation. Next Ariel started to think about problems to solve in healthcare which is when H1 was born out of in 2017. Around that time Ariel connected with Ian Sax. They are now co-founders leading H1.
